
Kubernetes 1.16 brought an exciting and important new feature called Endpoint Slices.
It’s currently in alpha (September 2019 on K8s 1.16), but it’s one I’m excited about and will be closely tracking.
Here’s the premise…
Everything is hard at scale, even Kubernetes. One part of Kubernetes that doesn’t scale well is Endpoints objects.
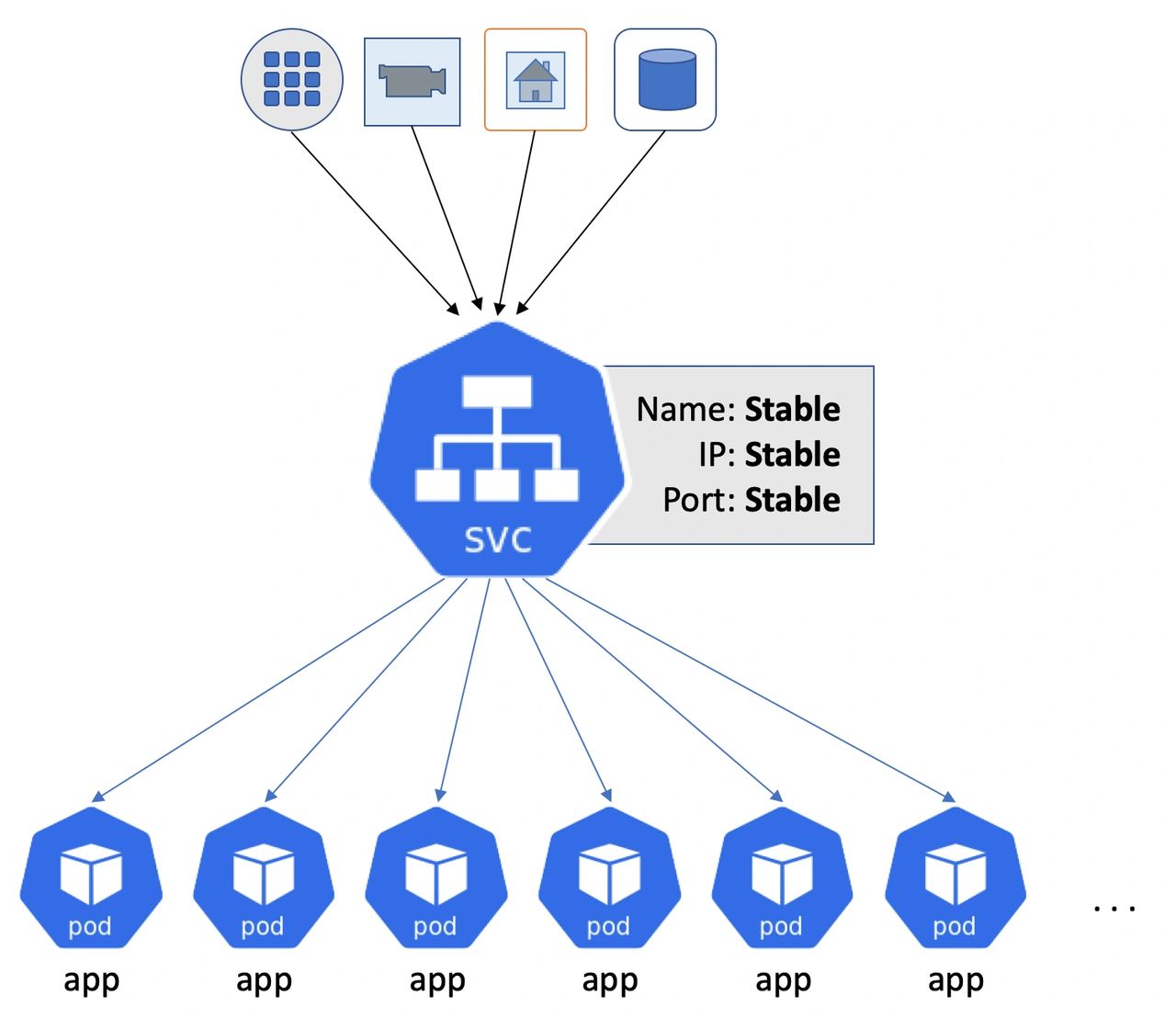
As things stand, you deploy applications to Kubernetes as a set of Pods. You then create Kubernetes Service objects (svc) that sit in front of your Pods to provide stable and reliable networking. In this model, everything talks to Services instead of directly to Pods.
Behind the scenes, every Service has an associated Endpoints object that’s a list of all the active healthy Pods that match the Service’s selector. You might have one Service that selects all the Pods that handle the front-end to your application, and another Service that selects on the Pods handling video rendering tasks. And everything works well, until you hit massive scale.
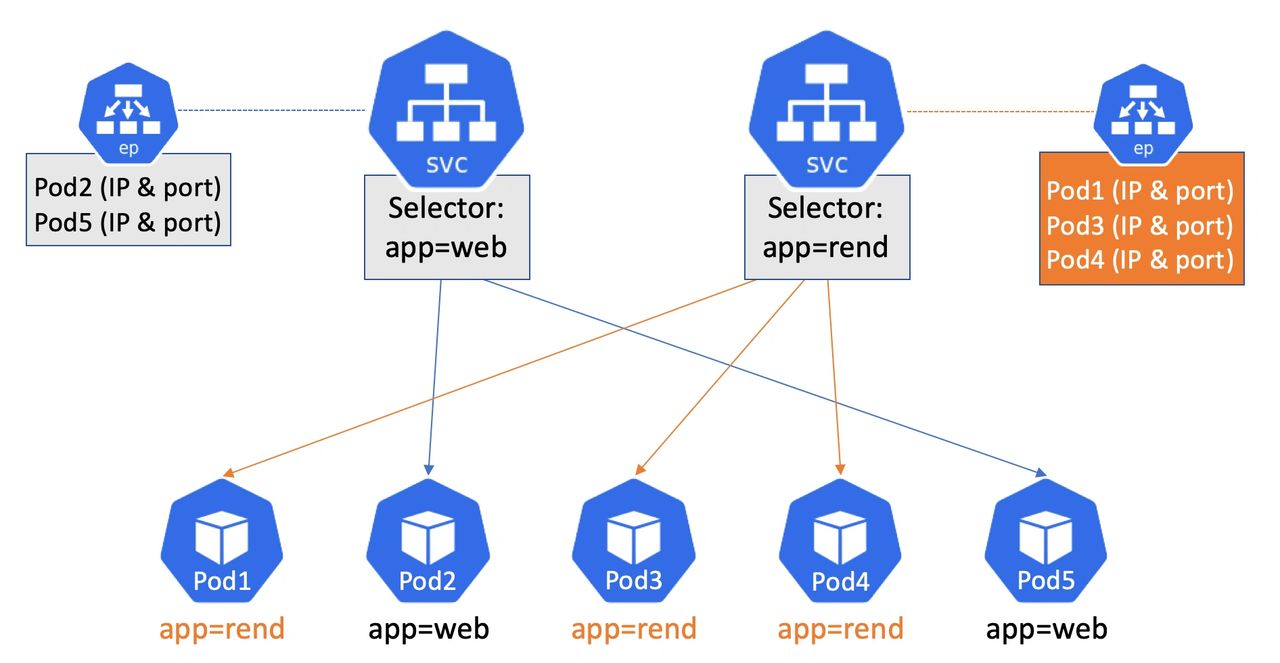
Assume you’ve got a Service sitting in front of lots and lots of Pods. The Service has an Endpoints object that holds the IP and port of every one of those lots and lots of Pods. This Endpoints object gets sent over the network to every node in the cluster and is used to create local networking rules etc.
The problem is…. every time you add or remove a Pod from behind the Service, the entire Endpoints object gets updated, sent across the network, and consumed by every node.
If that Endpoint object is large (we’re talking about large scale Kubernetes here) and you change just a single entry in it, **the whole thing** gets re-cut, re-sent across the network, and re-consumed by every node. And if you’re making lots of small changes, those lots of small changes result in lots of mahoosive network traffic and lots of hard labor for your nodes.
Enter Endpoint Slices…
The principle behind Endpoint Slices is pretty simple. Take that single large monolithic Endpoints object, and slice it up into smaller more consumable slices.
As things stand, its early days and Endpoints Slices are an alpha feature. This means things will get tweaked and changed before it’s promoted to stable (GA). However… as things stand… each Endpoint Slice will hold 100 actual endpoints — that’s lowercase endpoints, so it means an IP address and port of a Pod. Meaning each Endpoint Slice contains the network details for 100 Pods.
So, going back to our example of a Service selecting on lots and lots of Pods… This time, when we delete a Pod… Instead of re-cutting the entire Endpoints object, which might have thousands of Pods in it, Kubernetes only re-cuts the slice that holds the details for that Pod. This results in a much smaller slice being sent over the network and consumed by every node in the cluster.
Net results?
- Less network traffic
- Less hard labor for nodes
- Less hard labor for the control plane
- Better performance at scale
Boom!
I’ve also got a video explaining how it works. https://www.youtube.com/embed/f3xusisgp74
Now remember, we’re only scratching the surface here, and it’s early days and things might change. And as things develop I’ll be sure to explain it all here. But this is a great behind-the-scenes feature that’s gonna make your life a ton easier if your operating at scale.
Happy days!



