
Like most technologies, Kubernetes was slow to manage stateful apps and persistent data. In fact, there was a time when I thought it might never happen.
Fortunately, things are changing fast, and it’s mainly due to two things:
- Kubernetes now has the low-level primitives to integrate with enterprise-grade storage solutions
- Data management vendors are bringing their advanced storage systems to the party
One of those data management vendors is Commvault. So, let’s see what they’re bringing to the party…
Enter Commvault
Having been a happy Commvault customer in the early 2000’s, I was keen to take a look at their Kubernetes integrations.
Let’s just say I’m impressed!
At a high-level, they have a software-defined storage (SDS) platform with some pretty sweet Kubernetes integrations.
The storage bits
The storage platform is called the Hedvig Distributed Storage Platform, and it’s based on the Hedvig technology they acquired in 2019. As someone who specialised in storage for 10 years and wrote a book on the topic, the Hedvig has pretty-much everything you’d want from a modern cloud-native storage platform — it’s cloud-agnostic, software-defined, scale-out, does high availability, snapshots, replication, kernel-level changed block tracking (CBT), and loads more. But most importantly… it’s beautifully integrated with Kubernetes!
Kubernetes Integrations
The foundation of any Kubernetes-native storage platform is its Container Storage Interface (CSI) driver. Well… I can say with confidence that their Hedvig CSI driver is one of the most comprehensive and feature-rich I’ve seen. As well as dynamic provisioning, it supports dynamic volume expansion, raw block devices, and volume clones. Those are all big ticks in my book.
However, their CSI driver is only the start.
They also have a host of custom resources (CRD) that expose their advanced data management features to apps as native Kubernetes objects. Basically, the advanced Hedvig features look, smell, and feel like regular Kubernetes objects, meaning Kubernetes applications can leverage them like any other Kubernetes feature.
As a quick example, the following Kubernetes YAML file creates a policy to snapshot volumes every hour, and retain each snapshot for two hours. The snapshot engine and scheduling functionality all exist on the Hedvig, but everything is defined in Kubernetes YAML and instantiated via normal Kubernetes methods.
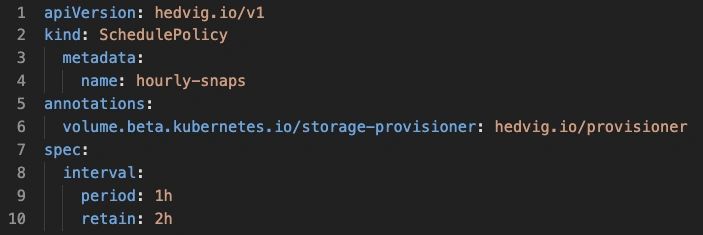
The following Storage Class object uses the Hedvig CSI driver (io.hedvig.csi) and references the “hourly-snaps” schedule policy shown above. As a result, any PVs created via this Storage Class will have hourly snaps that are kept for two hours. To be clear, the Hedvig cluster providing the volumes will perform the snapshot operations and manage retention.

There’s more…
We could talk for ages about the other integrations and potential use-cases. But keeping a long story short, there are integrations for scheduled snapshots, on-demand snapshots, topology-aware replication, multi-tenant policies, compression, dedupe, encryption at rest, SSD/flash, block storage, file storage, and more.
The following Storage Class YAML shows many of the potential options. However, it’s for illustration purposes only, as not all options are available on all configurations, but it gives you an idea of what is available.
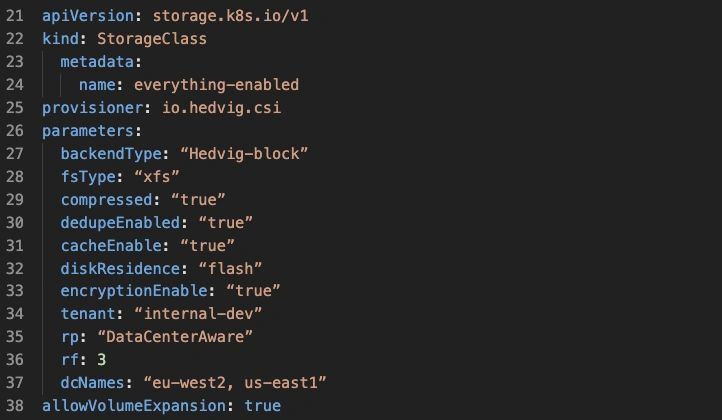
Finally…it’s cloud agnostic, works in your on premises data centre, is integrated into the Hedvig UI, and there’s some decent documentation. Plus… it can be backed by Commvault’s enterprise-class SLAs.
All of a sudden… the future of data management in Kubernetes looks so bright you probably shouldn’t stare at it 😉
Disclaimer
I’m a former customer of Commvault products and I have commercials in place to provide services for them. However, as always… I only partner with companies I believe in.



